30 Apr 2026
Engineering Leadership 2026: The Top Three Architectural and Operational Risks
As AI experimentation settles into operational reality, CTOs face compounding technical debt, fragmented infrastructure, and critical data provenance vulnerabilities.
The Shifting Landscape for 2026

The experimental phase of generative AI is ending. Over the past two years, engineering teams rushed to build prototypes, testing the boundaries of large language models and rapid cloud deployments. Now, leaders are tasked with moving those systems into production, integrating them into core architectures, and proving measured improvement. This transition from rapid prototyping to operational reality exposes deep structural weaknesses.
For CTOs, founders, and senior engineering leaders, the mandate leading into 2026 is no longer just about adopting new technologies to keep pace with the market. It is about practical implementation, securing the data supply chain, and managing the compounding technical debt of non-deterministic systems. Decisions made today regarding platform architecture, data governance, and workflow automation will determine whether your engineering organization scales efficiently or collapses under maintenance overhead.
This article details the three most critical risks technology companies face as they stabilize their architectures over the next 24 months. By understanding the mechanics of these risks and the trade-offs in mitigating them, you can better align your engineering investments to prioritize reliable delivery over fragile hype.
Risk 1: AI Implementation Debt in Agentic Systems
Integrating AI into enterprise software is fundamentally different from traditional software engineering. Standard applications rely on deterministic logic; given the same input, they produce the same output. AI agent implementation introduces non-determinism directly into your business logic.
The Core Mechanics of the Risk
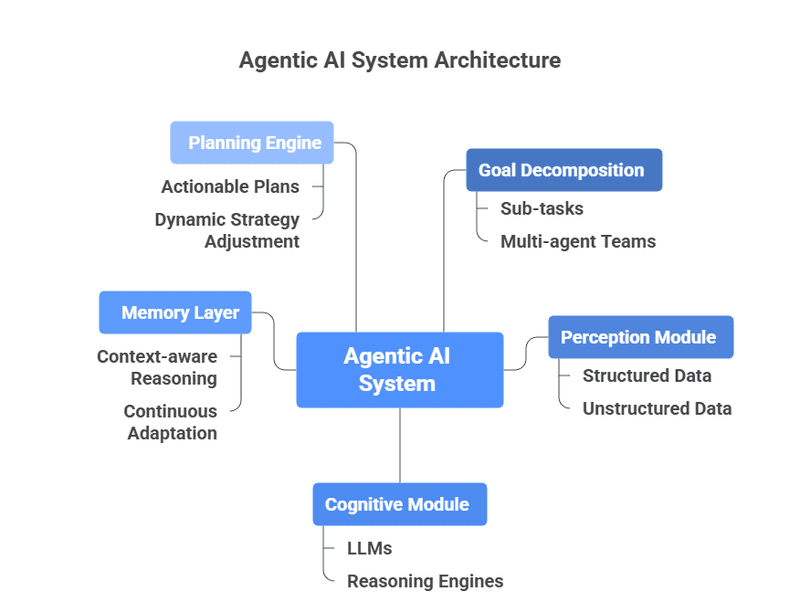
As organizations move beyond simple chatbots to autonomous agents that execute API calls, write to databases, or trigger downstream systems, the risk of compounding errors skyrockets. An AI agent might misinterpret a user prompt, hallucinate a parameter, and execute a tool call that corrupts state.
Furthermore, the cost of running these systems is highly variable. Unconstrained agentic loops—where an agent repeatedly attempts to solve a problem by querying an LLM, failing, and trying again—can lead to massive, unpredictable spikes in inference costs.
Architectures and Trade-offs
To manage this risk, engineering teams must shift their solution design from open-ended reactive loops to tightly constrained state machines.
- Open-Ended Agents: Fast to prototype, highly flexible, but fragile in production. They rely entirely on the model's reasoning capabilities to determine the next step. `Risk level: High` for production workflow automation.
- Graph-Based State Machines: Architectures that model workflows as directed acyclic graphs (DAGs). The LLM is only used for specific decision nodes, while the orchestration and tool execution are handled by deterministic code. This provides clear boundaries, measurable states, and easy fallback mechanisms.
Trade-off: Building graph-based state machines requires more upfront engineering and reduces the perceived "magic" of the AI, but it is mandatory for reliable delivery. You trade development velocity for operational stability and predictable costs.
Validation in Your Environment
Ask your engineering leads: "If our customer-facing AI agent gets caught in an infinite failure loop while calling an external API, how quickly do we detect it, and what stops the financial bleed?" If the answer relies on manual monitoring rather than hardcoded circuit breakers and token budgets, you carry significant implementation debt.
Risk 2: Infrastructure and Toolchain Fragmentation
The rapid evolution of data engineering and machine learning has triggered an explosion of specialized tools. Organizations are bolting vector databases, prompt registries, LLM routing gateways, and specialized evaluation frameworks onto their existing cloud footprints.
The Core Mechanics of the Risk
Approaching 2026, this fragmentation acts as a massive tax on developer productivity. When a request travels from a user interface, through a traditional API gateway, into a specialized AI router, hits a vector database for context retrieval, and finally calls an external LLM provider, observability breaks down.
Telemetry becomes siloed across different vendor dashboards. When a system slows down or fails, identifying the root cause—whether it is a latency spike from the LLM provider, a slow vector search, or a cold start in a serverless function—becomes an investigative nightmare.
Architectures and Operating Models
Mitigating this risk requires a mature platform engineering operating model. Instead of allowing individual squads to adopt disparate AI tools, leaders must enforce a unified internal developer platform (IDP).
- Ad-Hoc Tooling: High developer autonomy, rapid proof-of-concept creation, but leads to shadow IT, inconsistent security postures, and broken CI/CD pipelines.
- Unified AI Platform Control Plane: Centralizing AI infrastructure on a cohesive cloud foundation (like the patterns detailed in the Google Cloud Architecture Framework). This involves standardizing on a single vector storage solution, a unified gateway for all LLM traffic (to capture cost and latency metrics centrally), and standardized deployment pipelines for AI applications.
Trade-off: Centralization slows down the adoption of the "latest and greatest" specialized tools. However, for continuous improvement and enterprise scale, sacrificing a degree of tooling flexibility is necessary to maintain system-wide observability and reliable delivery.
Risk 3: Data Supply Chain and Provenance Vulnerabilities
Data has always been a target, but the architecture of modern AI applications introduces entirely new attack vectors and compliance nightmares. The most prevalent architecture for enterprise AI is Retrieval-Augmented Generation (RAG), which connects language models to internal data stores.
The Core Mechanics of the Risk
In a traditional application, Role-Based Access Control (RBAC) is enforced at the application tier. A user queries a database, and the application filters the results based on their permissions.
In a naive RAG implementation, vast amounts of unstructured enterprise data (documents, wikis, Slack messages) are chunked, vectorized, and dumped into a single database. When an employee asks an internal AI assistant a question, the system retrieves the most mathematically relevant text chunks and feeds them to the LLM. If access control context was stripped during the vectorization process, the AI might summarize highly sensitive HR data, executive financial planning, or proprietary source code, and present it to an unauthorized user.
Additionally, the risk of data poisoning is acute. If an attacker (or a careless employee) injects malicious instructions into a document that is later vectorized, the AI system may execute those instructions when retrieving the document—a vulnerability actively tracked in the OWASP Top 10 for LLM Applications.
Use Cases and Context
Consider a legal technology firm building a contract analysis tool. If they fail to isolate tenant data at the vector level, a query from Client A could retrieve context from Client B's highly confidential contracts. Relying on the LLM's system prompt to "not share confidential information" is entirely insufficient; language models cannot enforce data security policies.
Trade-offs and Constraints
The fundamental constraint is balancing retrieval latency with robust security.
- Metadata Filtering: Tagging every vector chunk with access control lists (ACLs). Before the vector search runs, it filters out chunks the user does not have permission to see. This is secure but requires a complex data engineering pipeline to keep vector ACLs synchronized with your primary identity provider (e.g., Active Directory or Okta).
- Separate Vector Stores: Provisioning entirely separate vector databases or isolated collections for different clearance levels or tenants. This is highly secure but increases infrastructure costs and operational overhead.
Trade-off: Implementing strict data provenance and access mapping significantly increases the upfront cost and time required for practical implementation. However, ignoring it guarantees a critical data breach as AI adoption scales internally.
Concrete Decision Criteria
To assess your organization's exposure to these three risks, use the following evaluation criteria during your next architecture review:
- AI Agent Reliability:
- Do we have hardcoded token limits and execution timeouts for every autonomous workflow?
- Can we fall back to a deterministic, non-AI process if the model provider experiences an outage?
- Infrastructure Telemetry:
- Can an engineer trace a single user request through the API gateway, into the vector search, through the LLM inference, and back out within a single observability dashboard?
- Are we tracking LLM API costs per product feature, or are they lumped into a single opaque cloud bill?
- Data Provenance:
- Does our data ingestion pipeline automatically tag vector embeddings with the source document's IAM permissions?
- Have we conducted an offensive security review specifically targeting prompt injection and RAG data leakage?
Common Pitfalls Avoided by Serious Teams
- Treating Prompts as Code: Less mature teams store complex LLM instructions in application code. Serious teams treat prompts as configuration, managing them in distinct registries with version control and separate deployment lifecycles.
- Ignoring the "Day 2" Operations: Many founders celebrate a successful AI launch without establishing clear ownership for evaluation. Models drift, APIs change, and user behavior shifts. Without automated evaluation pipelines running against a golden dataset, workflow automation degrades silently over time.
- Slapping LLMs on Unclassified Data: The most dangerous pitfall is pointing an AI reading tool at an unclassified, unstructured data lake. Establishing data governance and classification must precede AI integration, not follow it.
Takeaways
- Constrain Non-Determinism: Move away from open-ended autonomous agents. Embrace graph-based state machines that strictly bound what AI can execute within your workflow automation.
- Demand Unified Observability: Stop the sprawl of single-purpose AI tools. Centralize your AI infrastructure behind internal gateways to ensure you can measure latency, error rates, and costs from a single vantage point.
- Map Identity to Vectors: Never separate data from its access control context. If your RAG architecture does not enforce your existing identity and access management policies before the LLM sees the data, it is not ready for production.
- Focus on Measured Improvement: Discard features that rely on the novelty of AI. If an AI implementation does not demonstrably reduce cycle time, cut costs, or increase revenue—while maintaining strict security boundaries—it is technical debt.
Join the newsletter
Enjoyed this article? Get more like it in your inbox every week.
* 200+ tech professionals already in.
Next read
28 Jul 2026
5 Architectural Strategies to Unlock AI’s Full Potential
Move beyond prototype LLMs. Discover five architectural strategies to build reliable, grounded, and measurable AI systems that deliver real business value for the enterprise.
20 Jul 2026
Engineering an Agentic Workforce: Using Google Workspace
Examine how enterprises use Google Workspace and Vertex AI to shift from basic generative chat to secure, multi-step agentic workflows that drive measurable improvement.
13 Jul 2026
Responsible and Explainable AI: A Practical Guide for Engineering Leaders
Move beyond compliance. Learn how to architect AI systems that balance model performance with transparency, safety, and operational governance for reliable delivery.