25 May 2026
Measuring AI Agent Success: Metrics, Telemetry, and Business Impact
Define clear success metrics for AI agents. Learn how technical leaders measure task completion, autonomy rate, and cost-per-outcome beyond standard LLM benchmarks.

Deploying an AI agent is fundamentally different from deploying traditional software or a standard generative AI chatbot. While a chatbot generates text for a user to evaluate, an agent executes a workflow autonomously. It reasons, uses tools, interacts with external systems, and makes decisions to reach an objective.
Because agents take action, traditional system metrics like uptime, latency, and throughput are necessary but insufficient. Standard LLM metrics like token generation speed or text similarity scores also fall short. If you deploy an agent to process complex supplier invoices, knowing that it generates tokens quickly is irrelevant. What matters is the percentage of invoices processed accurately without human intervention.
For CTOs and senior engineering leads, establishing the right success metrics directly impacts solution design and resource allocation. Measuring the wrong things leads to AI implementations that demo well but fail to deliver measured improvement in production. This article covers how to design an evaluation framework for AI agents, what metrics actually correlate with business value, and how to build the telemetry required for reliable delivery.
Core Mechanics of Agent Evaluation
Evaluating an AI agent requires separating the underlying language model's performance from the agent's actual execution. An agent's success is defined by its ability to navigate a multi-step process.
Effective AI agent implementation measures performance across three distinct layers:
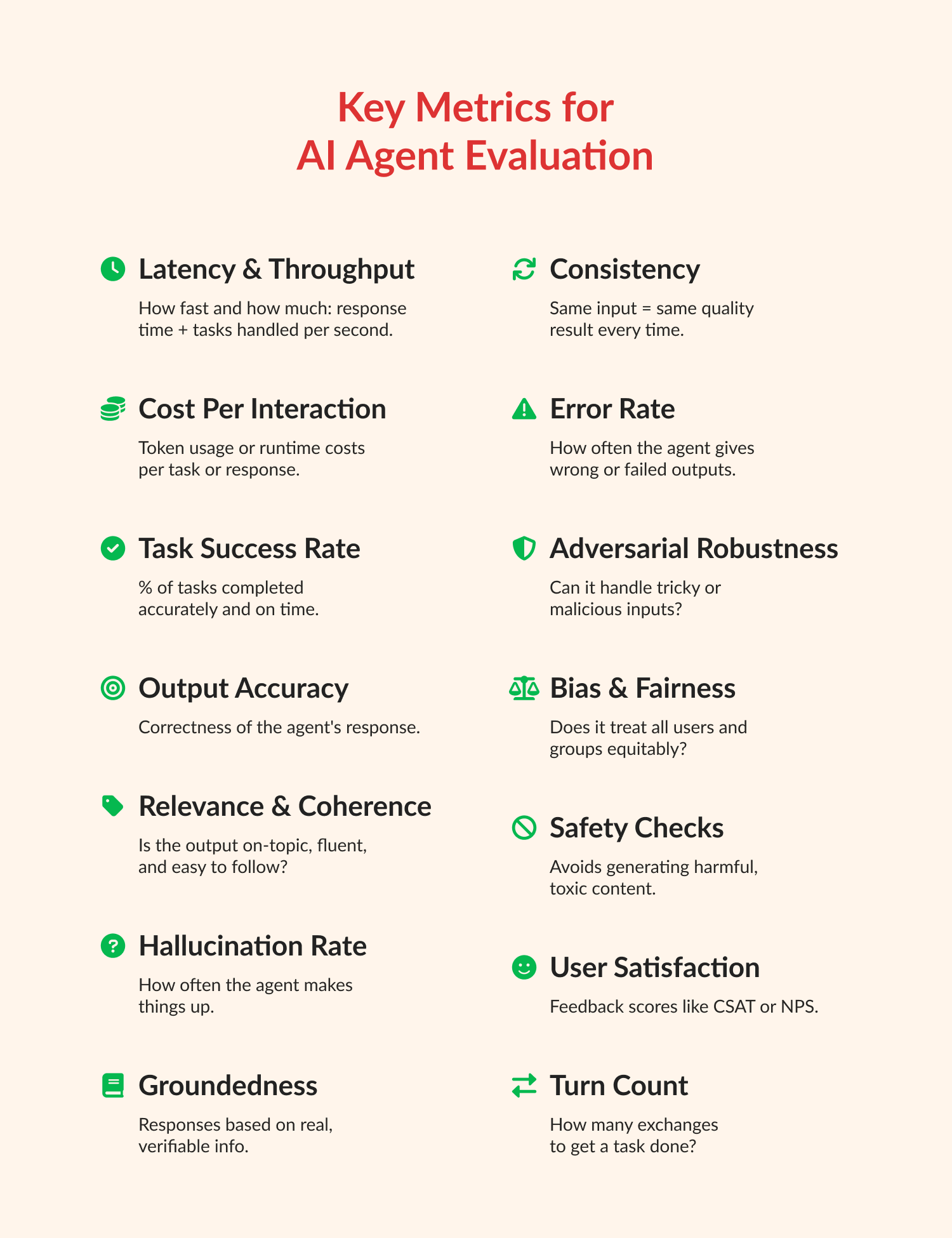
1. The Outcome Layer (Business Value)
This layer measures whether the agent accomplished its core goal. It tracks the ultimate utility of the workflow automation.
- Task Success Rate (TSR): The percentage of initiated workflows that reach a correct, verified conclusion.
- Autonomy Rate / Intervention Rate: The percentage of tasks completed without requiring a human-in-the-loop (HITL) handoff.
- Cost Per Action (CPA): The total compute and API cost required to complete one successful task. Agents often enter loops or retry failed API calls; CPA ensures the agent's operating cost remains viable compared to human labor or deterministic scripts.
2. The Execution Layer (Trajectory)
Agents do not just yield an output; they generate a *trajectory*—a sequence of thoughts, actions, and observations.
- Tool Selection Accuracy: Did the agent choose the right internal API or function for the step?
- Parameter Formatting: When calling a tool, did the agent format the JSON or query correctly according to the schema?
- Trajectory Efficiency: How many steps did the agent take to reach the goal? If an agent solves a problem in 12 steps that should take 3, it indicates poor reasoning or fragile prompt design.
- Recovery Rate: When a tool returns an error (e.g., a 404 from a database), how often does the agent successfully understand the error, correct its parameters, and retry successfully?
3. The System Layer (Infrastructure)
This relies on standard software observability but requires specific tuning for agent architectures.
- End-to-End Latency: The total time from trigger to task completion. Because agents think in loops, this can range from seconds to minutes.
- Tool Latency: The response time of the external systems the agent relies on. Slow tools cause the agent to idle, driving up overall latency and tying up compute resources.
Telemetry Patterns and Operating Models
To capture these metrics, engineering teams must implement specialized telemetry. Traditional logging struggles with agents because the execution path is non-deterministic. A single user request might trigger one API call or five, depending on the agent's internal reasoning.
Trace-Based Observability
To measure trajectory efficiency and tool accuracy, you need to log the entire execution graph. Every agent invocation must generate a trace that records the exact prompt, the LLM's raw output, the parsed tool call, the tool's response, and the next iteration.
Frameworks for agent tracing, such as the concepts outlined in LangSmith's tracing architecture, allow teams to visualize the steps an agent takes. On Google Cloud, teams often use Vertex AI Evaluation alongside standard Cloud Logging to capture this multi-step execution data. Without deep tracing, debugging a failed agent workflow devolves into guesswork.
LLM-as-a-Judge
For outcome metrics, determining if an agent "succeeded" is rarely as simple as checking a boolean flag. If an agent drafts an email to a customer resolving a billing dispute, how do you score the quality of that resolution at scale?
Modern agent operating models rely on the LLM-as-a-Judge pattern. You deploy a secondary, often larger model (like Gemini 1.5 Pro) to evaluate the output of the primary agent against a specific rubric. The judge model checks for tone, policy adherence, and factual accuracy.
Offline Golden Datasets
Continuous improvement of AI agents requires regression testing. Before deploying a new prompt or changing an underlying model, teams run the agent against an offline "golden dataset" of historical, verified tasks. The success metric here is the delta: did the update improve the Task Success Rate on known edge cases without increasing the Cost Per Action?
Applied Use Cases and Success Signals
Metrics only matter when mapped to practical implementation. Here is how success is measured across common agent patterns.
1. Customer Support Resolution Agent
Unlike a FAQ chatbot, a support agent has access to billing APIs, order databases, and ticketing systems. It is expected to resolve the issue, not just provide links.
- Primary Metric: First Contact Resolution (FCR) rate performed entirely autonomously.
- Secondary Metric: Human Handoff Rate. Crucially, the metric tracks graceful handoffs (where the agent summarizes the context for the human agent) versus hard failures (where the agent crashes or gets stuck in a loop).
- Constraint Metric: Policy Violation Rate. Did the agent offer a refund outside of the defined business rules?
2. Document Intelligence and Extraction Agent
This agent monitors an inbox, reads complex, unstructured PDF contracts, extracts key clauses, and updates a structured database or ERP system.
- Primary Metric: Schema Adherence Rate. What percentage of database entries exactly match the required data types?
- Secondary Metric: Recall and Precision. When evaluated against human-extracted baselines, did the agent find all relevant clauses (recall) without hallucinating non-existent terms (precision)?
- Constraint Metric: Trajectory Efficiency. Extraction agents can get stuck reading irrelevant pages. Tracking the number of read operations per document highlights inefficiencies.
3. IT Operations and Remediation Agent
An agent triggered by monitoring alerts that investigates server logs, restarts services, or rolls back configurations.
- Primary Metric: Mean Time to Remediation (MTTR) for agent-handled incidents.
- Secondary Metric: False Positive Action Rate. How often did the agent take a destructive action (like restarting a healthy node) based on a misinterpretation of logs?
- Constraint Metric: Blast Radius. Measured by strict adherence to Role-Based Access Control (RBAC) boundaries during tool execution.
Trade-offs, Risks, and Constraints
Setting up metrics for autonomous systems involves distinct architectural and business trade-offs.
The Cost of Evaluation vs. The Cost of Failure
Running an LLM-as-a-judge on 100% of your agent's transactions effectively doubles (or triples) your API costs. For high-stakes workflows (e.g., automated stock trading, legal compliance), this cost is necessary. For low-stakes workflow automation (e.g., summarizing meeting notes), it is prohibitive.
Trade-off: Teams must sample their evaluation. You might use deterministic checks (regex, schema validation) on 100% of agent runs, but only route 5% of runs to an LLM judge for qualitative grading.
Deterministic Checks vs. Probabilistic Scoring
LLM judges are probabilistic; they can hallucinate or show bias. Relying solely on an LLM to grade another LLM introduces a risk of "blind spots."
Constraint: Whenever possible, anchor your success metrics to deterministic outcomes. Did the database row update? Did the API return a 200 OK? Did the final email send? Use probabilistic metrics to grade the *quality* of the steps, but use deterministic metrics to grade the *fact* of the outcome.
Latency vs. Safety
Adding telemetry, evaluation rails, and multiple reasoning steps makes the agent slower.
Risk: If the agent is user-facing, high latency destroys the user experience. You may need to stream intermediate thoughts to the user to keep them engaged, or move the workflow entirely asynchronous. For backend batch processes, latency is less of a concern, and you can prioritize rigorous multi-step verification.
Decision Criteria for Measurement Frameworks
When designing your measurement approach, use these criteria to determine how heavy your telemetry and evaluation layers need to be.
Level 1: Low Autonomy / Read-Only
- Characteristics: Agent searches data, summarizes, but takes no external actions.
- Measurement Focus: Latency, user thumb-up/down feedback, standard retrieval metrics (Context Relevance).
- Evaluation Model: Occasional LLM-as-a-judge sampling. High reliance on end-user implicit feedback.
Level 2: Medium Autonomy / HITL Actions
- Characteristics: Agent drafts emails, stages database commits, or prepares code, but a human must click "Approve."
- Measurement Focus: Acceptance Rate (how often the human accepts the draft without edits), Time Saved per Task.
- Evaluation Model: The human acts as the judge. Telemetry tracks the delta between the agent's draft and the final human-edited version.
Level 3: High Autonomy / Write Access
- Characteristics: Agent processes refunds, modifies infrastructure, or sends communications independently.
- Measurement Focus: Task Success Rate, Tool Selection Accuracy, Cost Per Action, strict constraint monitoring.
- Evaluation Model: Deep trace-based observability. 100% deterministic outcome tracking. Pre-deployment regression testing against golden datasets is mandatory.
Common Pitfalls and How Serious Teams Avoid Them
1. Measuring speed over accuracy Many teams optimize for token generation speed to make the agent "feel" faster. However, in autonomous workflows, a fast failure is still a failure. Serious teams optimize for Trajectory Efficiency—getting to the right answer in fewer, high-quality steps, even if those steps take slightly longer to compute.
2. Treating agents like linear software Traditional monitoring sets alerts for any API failure. But agents are designed to encounter errors, realize their mistake, and try again. Alerting on a single failed tool call creates alert fatigue. Instead, engineering teams must alert on Failure to Recover—when the agent exhausts its loop limit without achieving the goal.
3. Ignoring negative side effects An agent told to "resolve customer tickets quickly" might start issuing maximum refunds to everyone to close tickets instantly. Success metrics must always be paired with constraint metrics. If Task Success Rate goes up, but Average Refund Cost spikes, the agent is optimizing the wrong path. Clear ownership of both the agent and the business metrics is required to catch these misalignments.
Practical Takeaways
- Define the outcome deterministically: Before building the agent, define exactly what system state changes indicate success (e.g., an updated CRM record, a closed Jira ticket).
- Track the trajectory, not just the output: Implement trace-based observability to log the agent's intermediate reasoning and tool calls. You cannot fix what you cannot trace.
- Pair success metrics with constraint metrics: For every metric that encourages the agent to complete a task, establish a metric that limits its behavior (e.g., cost boundaries, latency limits, strict schema requirements).
- Adopt LLM-as-a-judge for quality at scale: Use a secondary, highly capable model to grade the qualitative outputs of your agent, but sample the data to control API costs.
- Measure the human delta: In human-in-the-loop systems, the most important metric is the Acceptance Rate. If humans are constantly rewriting the agent's output, the workflow automation has failed, regardless of what the underlying LLM benchmarks say.
Join the newsletter
Enjoyed this article? Get more like it in your inbox every week.
* 200+ tech professionals already in.
Next read
28 Jul 2026
5 Architectural Strategies to Unlock AI’s Full Potential
Move beyond prototype LLMs. Discover five architectural strategies to build reliable, grounded, and measurable AI systems that deliver real business value for the enterprise.
20 Jul 2026
Engineering an Agentic Workforce: Using Google Workspace
Examine how enterprises use Google Workspace and Vertex AI to shift from basic generative chat to secure, multi-step agentic workflows that drive measurable improvement.
13 Jul 2026
Responsible and Explainable AI: A Practical Guide for Engineering Leaders
Move beyond compliance. Learn how to architect AI systems that balance model performance with transparency, safety, and operational governance for reliable delivery.