17 Apr 2026
How to Develop Multi-Agent Architectures Correctly and Budget Effectively
Multi-agent systems solve the reliability limits of single LLMs, but they can easily derail cloud budgets. Learn how to architect, control costs, and ship predictable agent workflows.
Moving Beyond the Monolithic Prompt

When a single Large Language Model (LLM) is tasked with executing a complex, multi-step business process, it usually fails. The context window clutters, reasoning degrades, and the model loses track of its original instructions. Single-agent systems work well for narrow tasks, but workflow automation requires a different approach.
Multi-agent architecture solves this by dividing complex workflows among several specialized AI agents. Each agent has a distinct role, isolated context, and specific tools. Instead of one massive prompt trying to do everything, you build a system where a "Planner" agent delegates to a "Researcher" agent, which hands off to an "Analyst" agent.
For CTOs and senior engineering leads, deciding to build a multi-agent system introduces immediate trade-offs. The primary challenge shifts from prompt engineering to system orchestration, state management, and strict cost control. Because agents interact dynamically and trigger multiple LLM calls per step, token consumption can grow exponentially if left unchecked.
By the end of this guide, you will understand how multi-agent mechanics work, the architectural patterns that dictate system behavior, and exactly how to construct these systems without your inference budget spiraling out of control.
Core Mechanics: How Multi-Agent Systems Actually Work
At its core, a multi-agent system is a distributed software architecture where the "nodes" are LLM-backed decision makers. To make this work in practical implementation, three mechanical layers must be established:

- State Management: Agents need a shared understanding of what has happened. This is usually handled via a shared "scratchpad" or state graph. When Agent A finishes a task, it updates the global state so Agent B can pick up the thread without needing the entire historical transcript.
- Routing and Orchestration: The system needs rules for who talks to whom. If a task fails, does the agent retry, or does it pass the failure back to a supervisor? Orchestrator code dictates these transitions.
- Tool Execution: Agents must interact with the outside world (APIs, databases, internal systems). In multi-agent setups, tools are partitioned. A "Database Query" agent has SQL read access, while the "Email Draft" agent only has text-generation capabilities. This limits security blast radiuses.
Frameworks like LangGraph multi-agent patterns or AutoGen provide the scaffolding for these mechanics, allowing engineering teams to define nodes (agents) and edges (communication rules).
Architectural Patterns and Trade-Offs
The way you arrange your agents determines the system's autonomy, latency, and cost. There are three primary execution models, each suited to different business constraints.
1. Sequential Pipeline
This is the most predictable pattern. Agent A completes its task, formats the output, and passes it to Agent B.
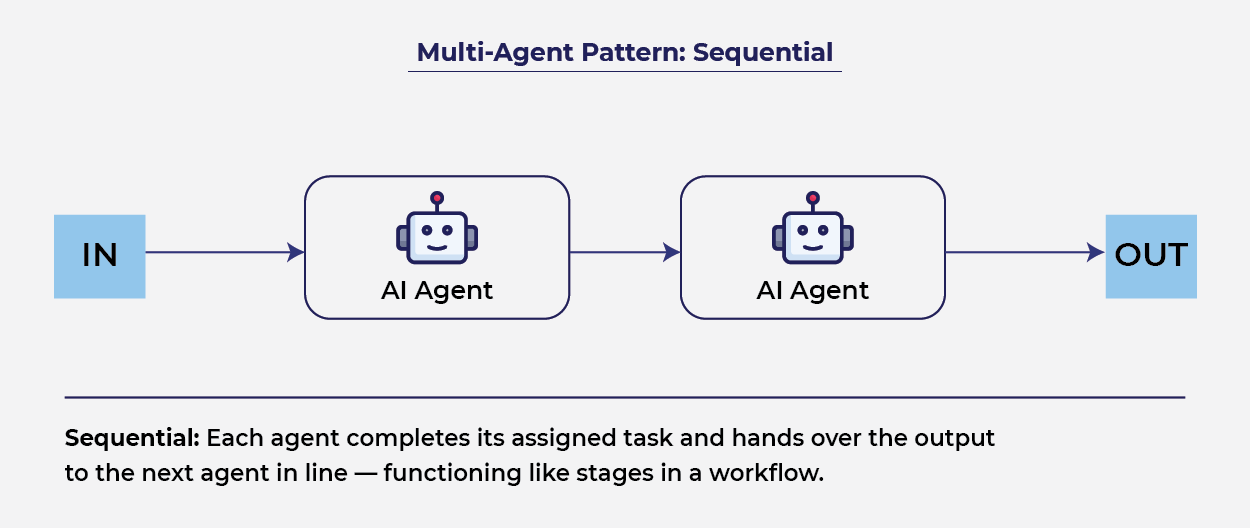
- Best for: Predictable workflow automation (e.g., Data ingestion -> Categorization -> Summary).
- Trade-offs: Highly predictable latency and strict budget control, but low flexibility. If Agent A makes a mistake, Agent B will likely amplify it, as there is no feedback loop.
2. Supervisor (Hierarchical)
A single "Router" or "Supervisor" agent receives the user request, breaks it down, and delegates tasks to specialized worker agents. The workers report back to the supervisor, who evaluates the work and decides if the task is complete.

- Best for: Complex queries requiring multiple tools (e.g., A user asking, "How did Q3 sales compare to our competitor's public earnings?").
- Trade-offs: Introduces a single point of failure. The supervisor agent consumes a massive amount of tokens because it must read the output of every worker.
3. Network (Peer-to-Peer)
Agents interact freely based on predefined rules. An agent can ask another agent for help directly without going through a central router.
- Best for: Open-ended research, creative problem solving, and complex simulations.
- Trade-offs: Extremely high risk of infinite loops. Peer-to-peer setups are notoriously difficult to test deterministically and are the leading cause of runaway cloud costs in AI implementations.
Budgeting Effectively: Controlling the Burn Rate
Multi-agent architectures are prone to "token compounding." If five agents share a 10,000-token context window, and they iterate through a problem ten times, you have just consumed 500,000 tokens for a single query. To budget effectively, you must architect for cost efficiency from day one.
Tiered Model Routing
You do not need GPT-4o, Claude 3.5 Sonnet, or Gemini 1.5 Pro for every task. Serious teams implement model tiering.
- Use highly efficient, fast models for routing, data extraction, and structural formatting.
- Reserve frontier models exclusively for complex reasoning, final synthesis, or code generation.
Context Pruning
Never pass the raw conversational transcript from agent to agent. Instead, mandate that every agent summarizes its findings before passing the state forward. If an agent parses a 50-page PDF, it should hand off a 500-word structured JSON summary to the next agent, not the raw text.
Hard Limits and Checkpoints
To prevent runaway costs, orchestrators must have strict execution limits. Implement a maximum "step count" (e.g., the workflow automatically halts after 15 agent interactions). Furthermore, require human-in-the-loop validation for any loop that exceeds a specific budgetary threshold.
Semantic Caching
If agents frequently answer similar questions or fetch the same data, implement semantic caching at the orchestration layer. If a user asks a question with a 95% vector similarity to a question asked an hour ago, return the cached final state rather than waking up the agent swarm.
High-Value Use Cases
Multi-agent systems shine when a workflow requires distinct personas, conflicting objectives, or isolated toolsets.
Automated Quality Assurance (Generator-Critic)
One of the most reliable multi-agent patterns pairs a "Generator" agent with a "Critic" agent. The Generator writes code or drafts a report. The Critic agent, armed with a separate prompt detailing strict compliance or style guidelines, reviews the output and sends it back with corrections. This adversarial loop results in significantly higher-quality output than a single model attempting to "double-check" its own work.
Complex RFP and Proposal Generation
Responding to enterprise RFPs requires reading vast amounts of historical data, understanding compliance requirements, and writing persuasive copy. A multi-agent solution design separates this into:
- A Document Retriever agent that finds past answers.
- A Technical Assessor agent that flags missing architectural details.
- A Writer agent that unifies the voice.
This separation of concerns ensures that the Writer does not hallucinate technical specifications, as it is only allowed to use data provided by the Assessor.
Security Alert Triage
In a security operations center (SOC), a multi-agent workflow can triage thousands of low-level alerts. A Fetcher agent pulls logs from the SIEM; an OSINT agent checks external threat feeds; an Analyst agent compares the findings to internal playbooks. The final output is a structured recommendation for the human security engineer, drastically reducing manual investigation time.
Risks, Constraints, and What to Validate
Deploying multi-agent systems requires anticipating what will break when models interact in the wild.
- Latency Stacking: If an agent takes 4 seconds to respond, and a workflow requires 6 sequential agent hand-offs, the user is waiting 24 seconds. This is unacceptable for real-time applications. Multi-agent systems are almost always better suited for asynchronous, background workflow automation.
- Hallucination Cascades: If the first agent in a pipeline extracts the wrong ID from a database, every subsequent agent will work diligently on the wrong premise. You must implement validation gates (e.g., Pydantic schema enforcement) between agents to catch bad data early.
- Observability Black Holes: When an output looks wrong, debugging a single prompt is easy. Debugging a 4-agent conversation is a nightmare without proper telemetry. You must log the input, output, latency, and token count of every individual agent step. Referencing patterns in Google Cloud architecture center for AI observability can help structure these logs.
Decision Criteria: Choosing the Right Approach
Use these criteria to decide if and how to build a multi-agent system in your environment:
- Complexity vs. Scale: If the task is simple (e.g., standard text translation), stick to a single LLM. If the task requires specialized tools (e.g., compiling code, querying SQL, formatting PDF), use a supervisor multi-agent setup.
- Budget Tolerance: If inference budget is highly constrained, rely strictly on sequential pipelines with smaller models. Avoid peer-to-peer or swarm architectures completely.
- Latency Requirements: If the user expects a response in under 3 seconds, multi-agent is likely the wrong choice. Use multi-agent for asynchronous background jobs.
- Security Isolation: If parts of the task require sensitive database access while other parts touch public internet data, multi-agent is mandatory. Give the secure tools to an isolated agent that cannot communicate externally.
Common Pitfalls and How Serious Teams Avoid Them
Many engineering teams fail their first multi-agent implementation by treating it like a chatbot project rather than distributed systems engineering.
- Pitfall: Giving one agent too many tools. When an agent has 15 different API tools to choose from, its routing logic degrades, and it selects the wrong tools.
Solution: Create more agents with fewer tools (1-3 tools max per agent). - Pitfall: Relying on the LLM to manage state. Expecting the model to remember what happened three steps ago leads to context drift.
Solution: Store state externally in a database or structured JSON object, and pass only the relevant state slices to the agent at runtime. - Pitfall: Ignoring token analytics. Waiting for the end-of-month cloud bill to see what the agents cost.
Solution: Implement middleware that tracks token burn per workflow execution, triggering alerts if an agent loop exceeds a predefined dollar amount.
Takeaways
- Multi-agent is distributed computing: Treat agents as microservices. They need clear boundaries, specific tools, and explicit communication protocols.
- Control costs via architecture: Token compounding is the largest threat to budget. Use tiered models (fast/cheap for routing, large/expensive for reasoning) and enforce strict loop limits.
- State over transcript: Never pass full conversational history between agents. Compress context into structured summaries to maintain focus and save tokens.
- Start sequential: Before building complex, autonomous supervisor networks, validate your business logic with simple, step-by-step agent pipelines.
- Design for async: Latency stacks with every agent interaction. Implement these architectures for background workflow automation, not real-time user chat interfaces.
Join the newsletter
Enjoyed this article? Get more like it in your inbox every week.
* 200+ tech professionals already in.
Next read
28 Jul 2026
5 Architectural Strategies to Unlock AI’s Full Potential
Move beyond prototype LLMs. Discover five architectural strategies to build reliable, grounded, and measurable AI systems that deliver real business value for the enterprise.
20 Jul 2026
Engineering an Agentic Workforce: Using Google Workspace
Examine how enterprises use Google Workspace and Vertex AI to shift from basic generative chat to secure, multi-step agentic workflows that drive measurable improvement.
13 Jul 2026
Responsible and Explainable AI: A Practical Guide for Engineering Leaders
Move beyond compliance. Learn how to architect AI systems that balance model performance with transparency, safety, and operational governance for reliable delivery.